

Agent-readiness crossed from concept to measurable infrastructure this week. On April 17, as Cloudflare Agents Week extended into its sixth day, the company shipped isitagentready.com, a public scanner that scores any website on how prepared it is for AI agents. Paste a URL, get a score, see which checks passed and which failed, read AI-generated guidance on how to improve. For the first time, the agent-legibility conversation moved from "is my website ready for agents" as a gut feeling to "my website scored X out of 100 in these five categories, here are the failing signals."
The Agent Readiness Score is a real shift. It is also a structurally misleading tool if you stop reading after the composite score.
I ran the scan on this website (nohacks.co) and scored 33 out of 100, Level 2 "Bot-Aware." The robots.txt passed. The sitemap passed. The AI bot rules in robots.txt passed. Content Signals passed. Then the score collapsed across categories where a content-only blog genuinely doesn't need what the scanner checks for. More on that in a minute.
First, the context. Cloudflare has been shipping agent-facing infrastructure all week. The Agent Readiness Score arrived alongside Agent Memory, Shared Dictionaries, Redirects for AI Training, an LLM compression technique called Unweight, and a feature-flag tool called Flagship built for AI-generated code. Four days earlier they shipped Project Think (a new Agents SDK) and OpenAI matched it within hours with their own Agents SDK. I wrote about that earlier this week in The Agent Runtime Wars Started This Week. The readiness scanner is the logical next piece: if runtimes are the new browser layer, website owners need a way to test whether their website is legible to that layer. Cloudflare shipped the tester.
The question this article answers is narrower: what does the scanner actually check, what should you do with your score, and where is the scoring structurally misleading enough that the number by itself leads you astray?
Updated May 25, 2026: Added MPP (Machine Payment Protocol) as a new Commerce check added to the scanner after launch.
GET WEEKLY WEB STRATEGY TIPS FOR THE AI AGE
Practical strategies for making your website work for AI agents and the humans using it. Podcast episodes, articles, videos. Plus exclusive tools, free for subscribers. No spam.
Contents
- What Cloudflare shipped: scanner, API, and an MCP endpoint agents can call on you
- Sixteen checks, five categories: what the scanner actually tests
- nohacks.co scored 33/100, Level 2 Bot-Aware
- Same website scores 33 or 67 depending on the preset you select
- Agent readiness measures delivery, not message
- Three Goodhart risks built into the Agent Readiness Score
- Six weekend fixes that map to real agent runtimes
- Vendor-specific scanners are coming: track what every scanner tests
What Cloudflare shipped: scanner, API, and an MCP endpoint agents can call on you
The scanner is at isitagentready.com. Paste any URL, pick a website type (All Checks, Content Site, or API/Application) to scope which signals get scanned, hit Scan. The scanner fetches the homepage and a handful of well-known paths, runs a set of checks against each, and returns a scored report with pass/fail markers, status codes, response bodies, and AI-generated guidance on what to fix.
The scanner is also available three other ways:
- Integrated into Cloudflare Radar so the same checks run alongside Radar's existing URL analysis
- Exposed programmatically via the Cloudflare URL Scanner API for automation
- Available as a stateless MCP server at
/.well-known/mcp.jsonso any MCP-compatible agent can call the scan as a tool and reason over the result
The MCP server endpoint is worth sitting with for a moment. Cloudflare shipped an agent-readiness scanner that agents themselves can call to audit websites before deciding how to interact with them. The scanner checks whether your website is ready for agents, and any agent can invoke it to decide how to interact with you before arriving. The measurement and the measured are starting to share the same surface.
Back to the practical question. What exactly does it check?
Sixteen checks, five categories: what the scanner actually tests
The Agent Readiness scanner runs seventeen checks across five categories: Discoverability, Content, Bot Access Control, API/Auth/MCP Discovery, and Commerce. Here is what each one looks for.
Discoverability (3 checks). Whether the website publishes the basic metadata an agent needs to find what is where.
- robots.txt exists. The classic crawl-policy file. An agent that follows robots.txt needs it to exist and parse.
- sitemap.xml exists. Either declared via a Sitemap directive in robots.txt or available at the standard path. An agent that wants to enumerate pages uses the sitemap.
- Link headers (RFC 8288). HTTP Link headers pointing to canonical, alternate, or related resources. Useful for agents that parse responses rather than HTML.
Content (1 check).
- Markdown for Agents. Content negotiation. The scanner sends
Accept: text/markdownand checks whether the website returns Markdown instead of HTML. This is Cloudflare's own proposal rather than an IETF spec, though the mechanism (HTTP content negotiation via theAcceptheader) is standard. Real agent runtimes prefer Markdown because it is cheaper to tokenize and easier to parse than HTML. Some early movers (Cloudflare itself, a handful of docs websites) support Markdown content negotiation; most websites do not.
Bot Access Control (3 checks).
- AI bot rules in robots.txt (RFC 9309). Whether robots.txt contains directives for AI-specific user agents (GPTBot, ClaudeBot, PerplexityBot, etc.).
- Content Signals in robots.txt. An emerging spec for expressing per-URL access rules inside robots.txt. Parsed as
User-agent: *followed byContent-signal:directives. Adoption is minimal right now. - Web Bot Auth request signing. HTTP message signatures at
/.well-known/http-message-signatures-directorythat let agents prove their identity cryptographically. This is the Agent Name Service side of things Cloudflare shipped with GoDaddy earlier in Agents Week. Adoption is almost zero outside Cloudflare's own properties.
API, Auth, MCP & Skill Discovery (6 checks).
- API Catalog (RFC 9727). A machine-readable index of a website's API endpoints at
/.well-known/api-catalog. - OAuth / OIDC discovery (RFC 8414). Standard OAuth 2.0 authorization server metadata at
/.well-known/oauth-authorization-serverand/.well-known/openid-configuration. - OAuth Protected Resource (RFC 9728). A website declaring which endpoints are OAuth-protected and how to authenticate.
- MCP Server Card (SEP-1649). A Model Context Protocol server advertising its capabilities at
/.well-known/mcp/server-card.json. SEP-1649 is a draft proposal inside the MCP spec process. - Agent Skills index. A list of agent-callable skills at
/.well-known/agent-skills/index.json. Also emerging. - WebMCP (Experimental). An in-page JavaScript API registering agent-callable tools via
navigator.modelContext. The scanner uses headless browser rendering to detect whether the website registers any WebMCP tools on page load.
Commerce (4 optional checks, not scored on non-commerce websites).
- x402 payment protocol. HTTP 402 Payment Required infrastructure for agent-native payments.
- MPP (Machine Payment Protocol). An open standard for machine-to-machine payments via HTTP 402, co-developed by Tempo and Stripe. MPP extends the x402 pattern with support for session-based billing, multiple payment methods (cards, stablecoins, Lightning), and a challenge-credential-receipt flow. The scanner checks for an OpenAPI document at
/openapi.jsonwithx-payment-infoextensions on payable operations. Added to the scanner after launch. - UCP profile (Universal Commerce Protocol). Google's merchant-metadata standard at
/.well-known/ucp. - ACP discovery document (Agentic Commerce Protocol). At
/.well-known/acp.json.
The Commerce category is flagged "optional" on non-commerce websites. The scanner detects whether any e-commerce signals are present and, if not, displays the commerce checks for informational purposes without counting them in the score.
The Commerce category exclusion matters. It is evidence Cloudflare anticipated exactly the problem the rest of this article is about.
nohacks.co scored 33/100, Level 2 Bot-Aware
nohacks.co scored 33 out of 100, Level 2 "Bot-Aware," with Bot Access Control at 100 and API/Auth/MCP Discovery at 0.
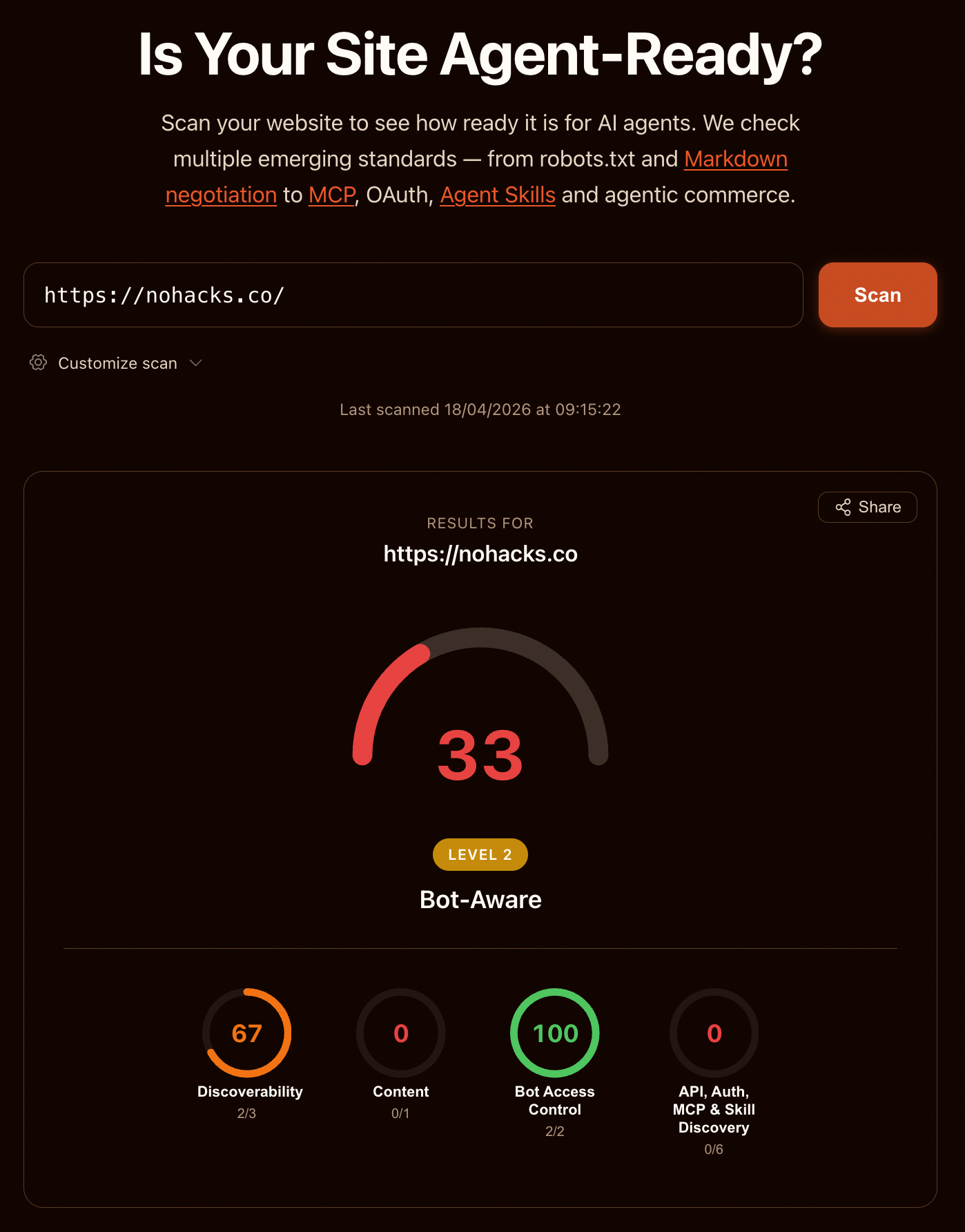 The Agent Readiness Score report for nohacks.co, scanned on 2026-04-18. Composite: 33 / Level 2 "Bot-Aware." Category breakdown: Discoverability 67 (2/3), Content 0 (0/1), Bot Access Control 100 (2/2), API, Auth, MCP & Skill Discovery 0 (0/6). Commerce checks not scored (no e-commerce signals detected).
The Agent Readiness Score report for nohacks.co, scanned on 2026-04-18. Composite: 33 / Level 2 "Bot-Aware." Category breakdown: Discoverability 67 (2/3), Content 0 (0/1), Bot Access Control 100 (2/2), API, Auth, MCP & Skill Discovery 0 (0/6). Commerce checks not scored (no e-commerce signals detected).
A note on that number: after the first scan I added Content Signals directives to robots.txt, which moved Bot Access Control from 50 to 100 and pulled the composite up eight points from an initial 25. Every other category below is unchanged from the first scan. I'll come back to the Content Signals fix and why I made it at the end of this section.
Here is what drove each category score:
- Discoverability: 67. robots.txt and sitemap.xml passed. Link headers failed because this website does not emit
Link:headers in its responses. - Content: 0. Markdown content negotiation is not configured. The website returns HTML regardless of the
Acceptheader. - Bot Access Control: 100. Both scored checks passed. AI bot rules in robots.txt (I have explicit rules for AI user agents) and Content Signals in robots.txt (I added these after the first scan). Web Bot Auth request signing is listed in this category as an informational check but not counted toward the 2/2.
- API, Auth, MCP & Skill Discovery: 0. All six checks failed. No API Catalog. No OAuth discovery. No OAuth Protected Resource metadata. No MCP Server Card. No Agent Skills index. No WebMCP tools on the page.
- Commerce: not scored. nohacks.co has no e-commerce. The Commerce checks all failed, but the category is correctly excluded from the composite score.
That is a 33 on a scanner built by the company I most trust to understand where the agent-ready web is going. I consider this website reasonably well-designed for agents. The robots.txt is clean and explicit. The content is server-rendered, machine-readable HTML with clean semantic structure. The sitemap is current. The URLs are stable. If you asked me a week ago whether this website was agent-ready, my answer would be somewhere between "mostly yes" and "for what it needs to do, yes."
And yet: 33, Level 2.
The scanner is measuring what it says it is measuring. The composite score, by itself, is still the wrong number to optimize for.
One note on the Content Signals fix, because it's relevant to the Goodhart argument later in this article. Content Signals is a Cloudflare proposal with almost no deployment beyond Cloudflare-aligned crawlers. I debated adding it for exactly the score-chasing reason this article warns about. I decided it was defensible for two reasons. First, the fix is declarative, not decorative. The directives state real policy about what should happen with my content, and the statement has meaning even if the spec fails. That is different from adding an empty MCP Server Card to satisfy a scorer. Second, for a website that writes about agent-readiness specifically, publicly declaring content policy is editorial practice regardless of which crawler respects it. The fix was one commit to public/robots.txt and the directives are readable by any human curious enough to check.
Same website scores 33 or 67 depending on the preset you select
On the All Checks preset, nohacks.co scores 33 out of 100, Level 2 "Bot-Aware." On the Content Site preset, same website, same day, different scan configuration, it scores 67, still Level 2 "Bot-Aware." Nearly double the composite score. The 34-point gap is the difference between two scan configurations of the same scanner, not a difference between two websites.
Here is what the Content Site preset changes in the scan configuration:
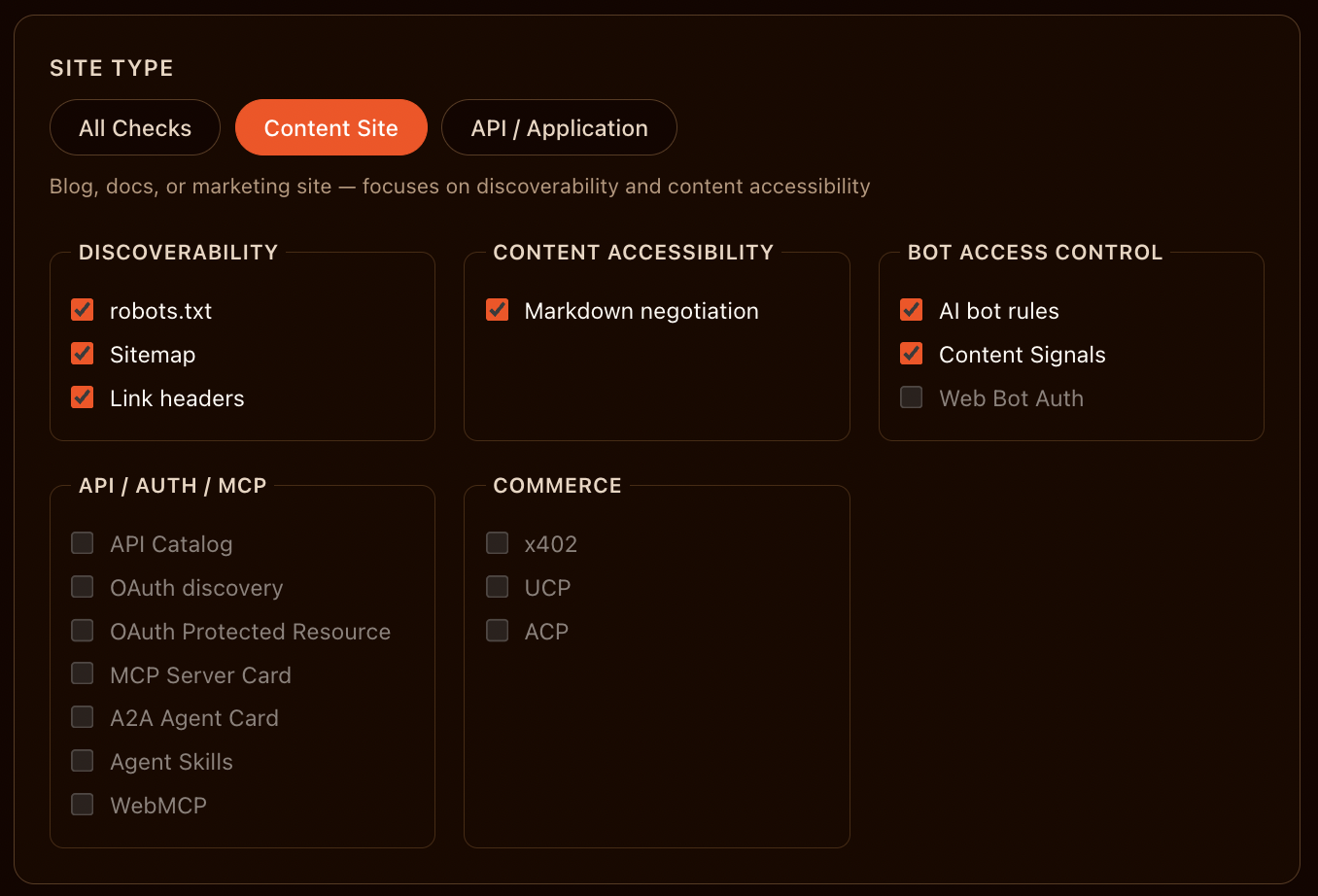 The Content Site preset unchecks every item in the API/Auth/MCP/Skill Discovery category, every item in the Commerce category, and Web Bot Auth in Bot Access Control. Six scored checks remain: three Discoverability (robots.txt, Sitemap, Link headers), one Content Accessibility (Markdown negotiation), two Bot Access Control (AI bot rules, Content Signals).
The Content Site preset unchecks every item in the API/Auth/MCP/Skill Discovery category, every item in the Commerce category, and Web Bot Auth in Bot Access Control. Six scored checks remain: three Discoverability (robots.txt, Sitemap, Link headers), one Content Accessibility (Markdown negotiation), two Bot Access Control (AI bot rules, Content Signals).
Running that preset on nohacks.co produced this result:
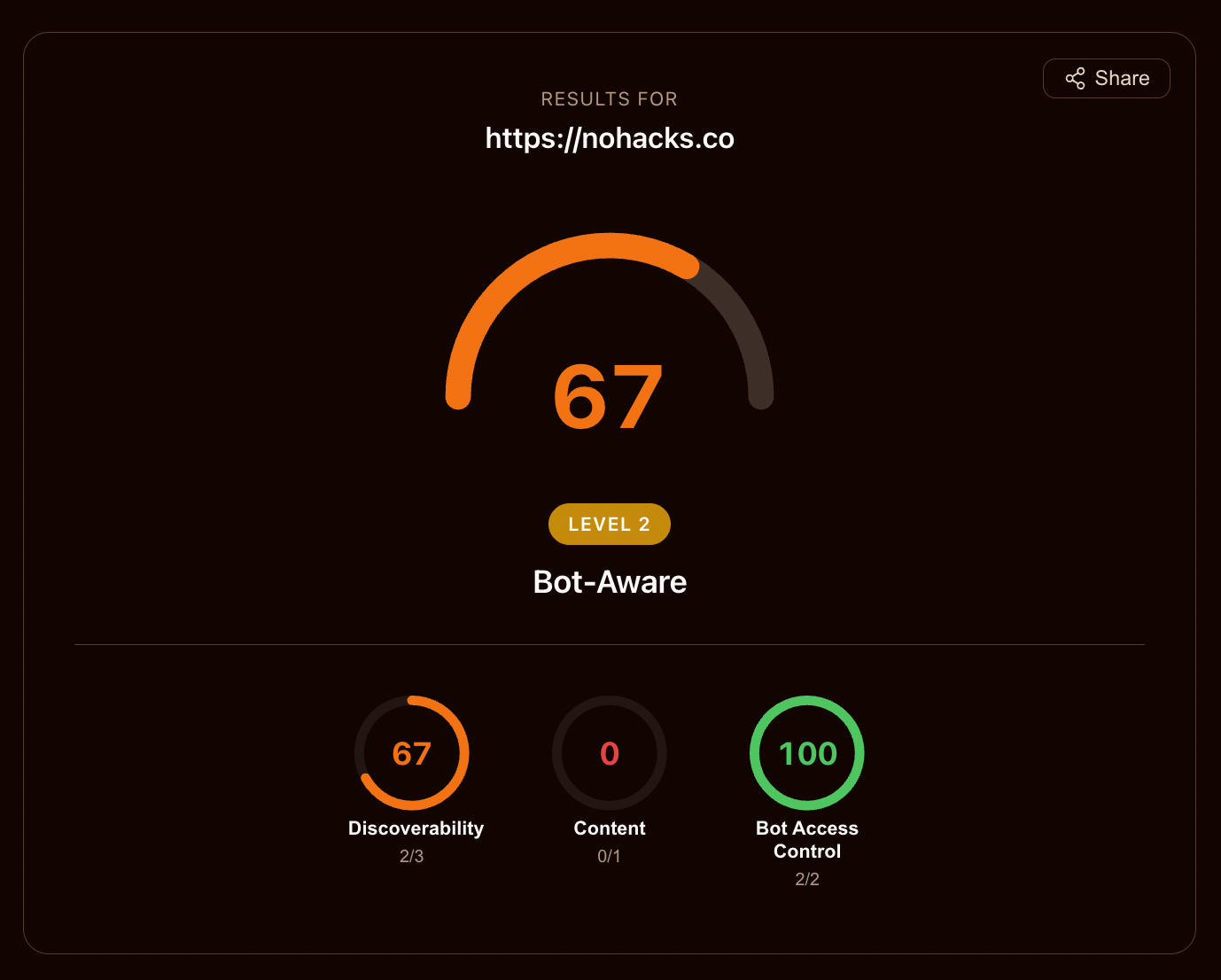 nohacks.co under the Content Site preset: 67 / Level 2 "Bot-Aware." Four of six scored checks pass. The two failing checks are Link headers (a fix I have not deployed yet) and Markdown content negotiation (not configured). Both are real shipping signals that agent runtimes benefit from today.
nohacks.co under the Content Site preset: 67 / Level 2 "Bot-Aware." Four of six scored checks pass. The two failing checks are Link headers (a fix I have not deployed yet) and Markdown content negotiation (not configured). Both are real shipping signals that agent runtimes benefit from today.
Four of six scored checks pass. The two failures are unambiguous remediation targets: Link headers via HTTP response configuration, Markdown content negotiation via origin or CDN response logic. Both ship against real agent-runtime behavior today. Neither is a proposal-stage format that will only maybe become a standard. This is the honest reading of nohacks.co's agent-readiness state: two specific, actionable gaps.
The correct toggle is hidden, and the default score is wrong
The scanner is doing its job. It knows a blog does not need an MCP Server Card. It knows a podcast archive does not publish an API catalog. The Content Site preset is not cosmetic. It removes irrelevant checks and gives a content website an accurate reading against standards that actually apply.
The problem is that the preset is hidden. When a user lands on isitagentready.com and pastes a URL, the default scan is All Checks. The Site Type toggle that would switch to Content Site or API / Application lives inside a Customize dropdown that most users will never open. The user clicks Scan, reads the composite score, takes a screenshot, shares it. The shareable number, the one that travels on social media, the one competitors compare across, is the All Checks composite.
For a content website that runs the default scan without reading individual checks, the composite is structurally too low. The 33 on nohacks.co is wrong for the kind of website nohacks.co is. The 67 from the Content Site preset is the accurate reading. Two numbers from the same scanner on the same website. The accurate number is behind a dropdown. The wrong number is on the front page.
Any web professional who runs the scanner and plans to share the score anywhere public needs to open Customize, select the preset that matches their website type, and re-run before sharing. Without that step, the public score will understate the website's actual agent-readiness, and the gap between the shared number and the accurate number will be larger for content websites than for API websites (which are closer to the All Checks baseline). Read the individual checks. Do not share a composite until you know which preset produced it.
For the record: the 67 is bothering me. I am going to go get the 100. I know exactly what the Goodhart section below is about to warn against, and I am going to do it anyway. Two fixes stand between me and the 100. Both are five-minute jobs. Both map to real agent-runtime behavior (Link headers for discovery, Markdown content negotiation for efficient agent parsing) so at least the motivation is legitimate and not pure score-chasing. That caveat is also exactly what score-chasers say. Public scores are a gravitational field. Even the person writing a long article about their unreliability ends up orbiting.
Agent readiness measures delivery, not message
Every category the Agent Readiness scanner tests is about delivery: discoverability, content negotiation, bot access, API discovery, commerce protocols. None tests the quality of the message itself.
The scanner never asks whether your headlines are clear, whether your product descriptions persuade, whether your content answers the query well, whether your writing is any good. Those are SEO and CRO questions. They occupy the discipline of making the message better. The Agent Readiness Score occupies a different discipline entirely. It asks whether an agent can fetch your content, parse the format it arrives in, authenticate against your endpoints, call your functions, pay for your outputs.
That is the distinction that matters. Classical web optimization (SEO, CRO) is about what you say and how persuasively you say it. Agent-readiness is about how you deliver what you say to a non-human reader. Two websites can publish word-for-word identical content. One serves it as server-rendered HTML with semantic markup, responds to Accept: text/markdown, exposes structured data, returns predictable response codes. The other serves it as a JavaScript-rendered single-page application with no content negotiation and an inconsistent error surface. The message is identical. The delivery is different. The agent-readiness score will be different. And it will be right to be different, because the delivery is what the agent interacts with.
This is also why agent-readiness fixes tend to be orthogonal to SEO and CRO work. You can improve an agent-readiness score without rewriting a single word of your content. You can also have world-class SEO content that scores a 10 on the agent-readiness scanner because none of your delivery pipeline was designed for machine consumers. SEO and CRO work the content layer. Agent-readiness works the transport and protocol layer. They are adjacent but not the same craft, and treating them as the same is the mistake that turns an agent-readiness project into a content-rewrite project and misses the actual fix.
The people who will do well over the next several years are the ones who stop arguing about which discipline matters more and start recognizing they occupy different layers of the stack.
Three Goodhart risks built into the Agent Readiness Score
Goodhart's law says that when a measure becomes a target, it stops being a good measure. The Agent Readiness Score is well-designed but it is also now a public, shareable, compared number, which produces three predictable behavioral failures in the wild.
The first risk is that website owners will optimize for the number rather than for real agent behavior. Add an MCP Server Card that points nowhere because the scanner wants one. Publish an Agent Skills index with no actual skills. Ship a WebMCP tool that does nothing just to pass the detection check. The score goes up and nothing changes for real agent runtimes visiting the website.
The second risk is that consultancies will start selling "Agent Readiness Score optimization" as a service, selling the score rather than the underlying architecture. The history of SEO gives us a century of data on how this plays out. PageRank became a target and a decade of link-spam economy grew up around it. Core Web Vitals became a target and a generation of performance-theater optimizations followed. The Agent Readiness Score is a better-designed metric than either of those were at launch, but the same gravity applies.
The third risk is that the scanner's inclusion of emerging standards as scored signals will accelerate the adoption of those standards past the point where they are ready to carry real traffic. The scanner checks for llms.txt, a proposed format for exposing website content to language models. llms.txt is not a ratified standard, has no governing body, and has competing proposals for how it should be structured. Including it as a scored signal gives it weight it has not earned in the ecosystem. A website owner looking to fix a failing check is the marginal adopter who tips a proposal into a de facto standard before the spec work is done.
None of these failure modes are hypothetical. They are how every public measurement score in the history of the web has played out. The Agent Readiness Score is better than most because Cloudflare is honest about what it is, because the per-check detail is available right alongside the composite score, and because the Commerce category correctly excludes itself on non-commerce websites. That honesty is a feature worth protecting. Website owners and the consultancy industry will be tempted to treat the composite score as the target anyway.
Do not do this.
Six weekend fixes that map to real agent runtimes
Six actions for a web professional running the scanner the weekend of its launch, ordered from highest-leverage to lowest:
-
Run the scan on your website. It takes about 30 seconds. Note the score and open the detailed report. The detail is where the signal is.
-
Fix the failing checks that ship against real agent runtimes today. These are the ones whose absence measurably hurts your website for agents visiting it right now:
- robots.txt. If missing, add one. If present, make sure it contains specific rules for AI user agents (GPTBot, ClaudeBot, PerplexityBot, Google-Extended, etc.).
- sitemap.xml. If missing, generate one and link it from robots.txt. Keep it current.
- Markdown content negotiation. Configure your origin or CDN to return
text/markdownwhen theAcceptheader requests it. Cloudflare's own AI Crawl Control has first-class support for this. Other providers require custom server logic. - Structured data. Ship schema.org JSON-LD for the content types your website publishes (Article, Product, Organization, BreadcrumbList). This is not a scored check but it is the highest-leverage fix for citation behavior across every agent runtime currently deployed.
-
Treat the proposal-stage formats as a watch list, not a checklist. llms.txt, Content Signals in robots.txt, Web Bot Auth, API Catalog, MCP Server Card, Agent Skills, WebMCP, MPP, ACP, UCP are all real working standards in some sense. They are not shipping against real agent-runtime behavior at scale yet. Watch them. Implement them when your stack has a reason to, not because the scanner flags them.
-
Ignore the composite score in your own tracking. Track individual check outcomes over time. A website that goes from 3 of 5 real-runtime checks passing to 5 of 5 has measurably improved even if the composite score barely moved because the 10 proposal-stage checks still fail.
-
Re-scan after changes. The scanner is fast, free, and available via the URL Scanner API if you want to script regression checks into your deployment pipeline.
-
Skip the consultancies selling Agent Readiness Score optimization. The work is straightforward enough that a half-day audit and a focused remediation sprint will beat any packaged service.
The scanner is the tool. The work is still the work.
Vendor-specific scanners are coming: track what every scanner tests
The Agent Readiness scanner is standards-list-shaped: a set of checks against a fixed list of protocols and formats, some ratified (RFC 8288 Link headers, RFC 9309 robots.txt rules, RFC 8414 OAuth discovery, RFC 9727 API Catalog, RFC 9728 OAuth Protected Resource), some emerging proposals (MCP SEP-1649, WebMCP, Content Signals, Web Bot Auth, x402, MPP, UCP, ACP, llms.txt). The next thing that happens in the ecosystem is predictable: other vendors will ship their own scanners against their own preferred lists. The overlap will be significant because most of the ratified standards are uncontroversial. The divergence will be in which proposals each vendor scores for.
That divergence is where the agent-readiness measurement story gets interesting. A Cloudflare scanner that checks for Web Bot Auth and UCP is making a bet. A Google scanner, if it ships, would check for some of the same things and some different ones (Google has UCP, does not have Web Bot Auth). A Perplexity scanner would check for yet another set. Website owners would see different scores from different scanners on the same website. The composite score, already not trustworthy, becomes vendor-specific.
The signal worth tracking is which checks show up in every scanner that ships. Those are the de facto standards. The checks that only show up in Cloudflare's scanner are Cloudflare's bets. Some will win. Most will not.
This is the pattern that made me comfortable publishing an article about a Cloudflare tool on the day it shipped. The Agent Readiness Score is real. The thesis behind it (agent-readiness is a measurable property) is the right thesis. The specific scorecard is version one of something that is going to have dozens of versions, each reflecting its vendor's bets. Web professionals should engage with the version-one scorecard, fix what it correctly flags as real, watch what it flags as emerging, and keep their own running list of which checks survive across every scanner that ships in the next six months.
That running list is the real agent-readiness standard. The composite score is the marketing layer.
Run the scan. Read the report. Fix what matters. Watch what might.